主導用改造的方式部署 Cloudera EDH 叢集 - 第二部
2018 年 1 月 23 日
作者:Benjamin Vera-Tudela、Brandon Freeman 和 Mladen Kovacevic
原文:Cloudrea
類別: CDH Hadoop HDFS
在主導用改造的方式部署叢集的三篇系列文章中,我們在這一篇用改頭換面的方式部署 Cloudera EDH 叢集 - 第一部份中以概論方式說明節點如何分類、磁碟配置組態以及部署叢集時要考慮的網路拓樸。
在本文「第二部份:服務與角色配置」中,我們進一步從堆疊著眼,探討部署Cloudera Enterprise 所包括的各種服務和角色。 CDH 有許多功能和組態,可滿足各種不同的需求。為了專注探討我們的課題,我們以三個不同的產品為主要對象,探討如何在企業中部署。這些配置保證可以滿足高可用性和全面的安全需求,同時設定一個穩定的叢集,無論內部部署或在雲端均支援持續擴充。
第二部份:服務與角色配置
您在設計下一個叢集的架構時有許多不同的途徑,取決於您的目標和您想要解決的問題。我們假定高可用性和安全性是必要條件。我們的目標是為基於不同目標運作的環境定義服務與角色配置的範例,由三種不同的產品定義– 分析資料庫、營運資料庫和資料工程。
如今利用這些產品可以輕鬆投入雲端發展。在2017 年稍早,推出Cloudera Altus Data Engineering,作為第一級平台即服務的雲端產品,讓您迅速提交工作到按需設定為負責資料工程工作負載的叢集。最近,雲端上的Cloudera Altus Analytic DB (Beta)平台即服務所提供的各個環境,其目標是超越SQL 的即時分析。
讓我們開門見山,在探討我們的產品中可用的服務與角色之安排和配置時,也討論如何設計內部部署或自訂雲端解決方案(未託管) 的架構。 請參閱Cloudera 產品頁面瞭解更多產品構思來建構專屬用途的叢集。
分析資料庫
分析資料庫是由下列一組核心、高層級的元件提供支援。
.png)
Navigator Optimizer 是一款Cloudera 產品,並未直接安裝在您的叢集上,相反的它是我們在Cloudera 提供的一種雲端服務,協助識別、卸載和最佳化從傳統RDBMS 系統移轉到Cloudera 叢集的工作負載。
相同的,BI Partners 可能無法直接在叢集內執行,雖然他們經常利用JDCBC/ODBC 連接Impala 服務,以利透過非例行的商業智慧查詢和/或有意義的報告來提供商業智慧。
Navigator、Hue、Hive-on-Spark、Kudu 和Impala 是叢集的一部分,需要一套其他服務,才能在整個生態系統中正確運作。
指派服務的方式可能如下圖所示:
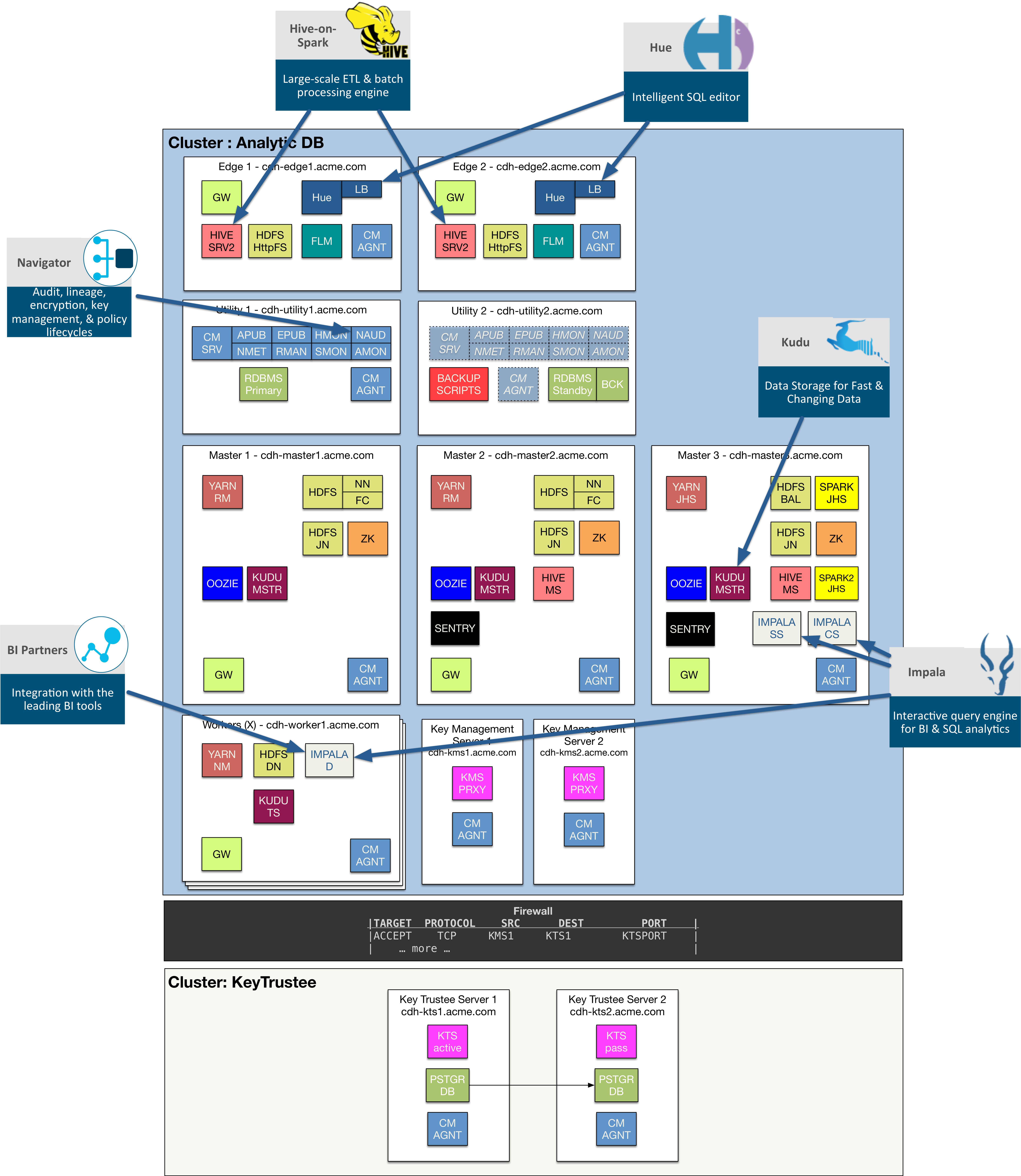
分析資料庫特定元件
Hue:Hue 伺服器常駐在邊緣節點上,必要時新增更多邊緣節點即可擴充。您也可以透過內建的負載平衡器使用Hue,而負載平衡器也可能安裝在多個邊緣節點上。使用者流量應該導向這些負載平衡器以利達成高可用性和高效能,因為不但使用者分散在多個Hue 伺服器上,負載平衡器也會快取靜態UI 元素,提升整體使用者體驗。
Cloudera Navigator:常駐在其中一個工具節點上,通常與Cloudera Manager 伺服器同址(co-located)。 它可能與其餘的Cloudera Management 服務一起執行,或是當叢集規模大幅擴張時,可能拉出來放在本身的工具節點上。
Hive:HiveServer2 服務常駐在邊緣節點上,必要時新增更多邊緣節點即可進一步擴充。Hive Metastore Servers 橫跨兩個主節點,且採用active-active 模式。
Spark 和Spark2:Spark 需要一個地方分別放置Spark 和Spark2 的JobHistory Server。我們把那些伺服器放置在其中一個主節點上。Spark 二進位檔安裝在整個叢集中,而Spark 的閘道服務常駐在邊緣節點和工作節點上。
Kudu:Kudu Master 角色部署在所有主節點之間,而Tablet Server 常駐在工作節點上。
Impala:Impala 的StateStore 和Catalog Service 安裝在單一主節點上。這些是無狀態的服務,表示當節點完全無法使用時,他們可以隨時在任何節點上再次啟動。Impala Daemons 安裝在所有工作節點之間,而第三方BI 工具可能與任何這些常駐程式連接來提交SQL 請求。 一般而言,這些請求會由第三方負載平衡器推動。
支援分析資料庫的其他核心元件
Cloudera Manager (CM):每一個叢集由部署在工具節點的CM 管理。同樣的,Cloudera Management Services 一般安裝在相同的工具節點上。第二個工具節點可以作為CM 的冷待命,意思是若第一個節點發生故障,我們可以在第二個工具節點安裝並啟動CM。
當然,我們也可以設定CM 利用負載平衡器達成高可用性,自動容錯移轉到待命的工具節點。CM 代理程式安裝在屬於該叢集的所有主機上。
請注意,在上圖中,實際上有兩個由CM 管理的叢集,一個用於分析資料庫叢集,而第二個用於KeyTrustee 叢集且支援全加密。
Metastore RDBMS:RDBMS 的Active-Standby 組態可使用工具節點。可以考慮在較少使用的第二個工具節點執行RDBMS 備份。
YARN:ResourceManager (Active-Standby) 和YARN JobHistory Server 散佈在多個主節點之間。YARN 閘道在邊緣節點而NodeManagers 常駐在所有工具節點。
HDFS:NameNode (Active-Standby)、JournalNodes、Failover Controllers 和HDFS Balancer 散佈在多個主節點之間。HDFS 閘道和HttpFS 執行個體部署在邊緣節點,而DataNodes 常駐在工具節點。
ZooKeeper:ZooKeeper 執行個體散佈在多個主節點之間。
Oozie:Oozie 以active-active 模式運作,而且可以擴充,或是萬一其中一台Oozie 伺服器故障時提供高可用性。建議把工作負載指向負載平衡器,由負載平衡器協助把流量導向可用的Oozie 服務。
Sentry:Sentry (Active-Standby) 伺服器在一對主節點之間運行。
Flume:Flume 服務常駐在邊緣節點上,只要新增更多邊緣節點便可以擴充。 請記得,您也可以在單一節點上執行多個flume 代理程式,只要代理程式用不同的連接埠互相監聽。
防火牆:CDH 叢集應利用防火牆與企業網路的其餘部分隔開,但是CDH 叢集與KeyTrustee 叢集之間也要有防火牆,如圖所示。
金鑰管理伺服器:常駐在一對專用節點上,而節點是CDH 叢集的一部分。
KeyTrustee Server:常駐在本身的KeyTrustee 叢集的一對專用節點上,由同樣管理CDH 叢集的Cloudera Manager 管理。它也包含一個資料庫和服務,在Active-Standby 模式中透明啟用。
營運資料庫
營運資料庫是由下列一組核心、高層級的元件提供支援:
在之前「支援分析資料庫的其他核心元件」一節說明過的許多核心元件亦支援營運資料庫元件。我們在這一節特別提及Navigator Encrypt 和Key Trustee,不過加密可適用於任何叢集。
HBase、Kudu 和Solr 提供各種低延遲插入、更新、刪除和擷取儲存的選項,供各種不同的營運使用案例使用。Hue 增強了Solr 的功能,這也是我們在這個叢集中納入Hue 的原因,以便馬上提供一個建立「Search」儀表板的方式。
在這裡使用Spark,不但為了強大的處理功能,也是為了SQL 以及串流功能,以便把資料快速帶到這個叢集中。
最後,透過串流,我們納入專供Kafka 使用的叢集,它在許多串流架構中均是主要元件,特別是來自上游生產生的渠道,並由Spark Streaming 消費者把資料存放在HBase、Kudu 或Solr。
指派服務的方式可能如下圖所示:
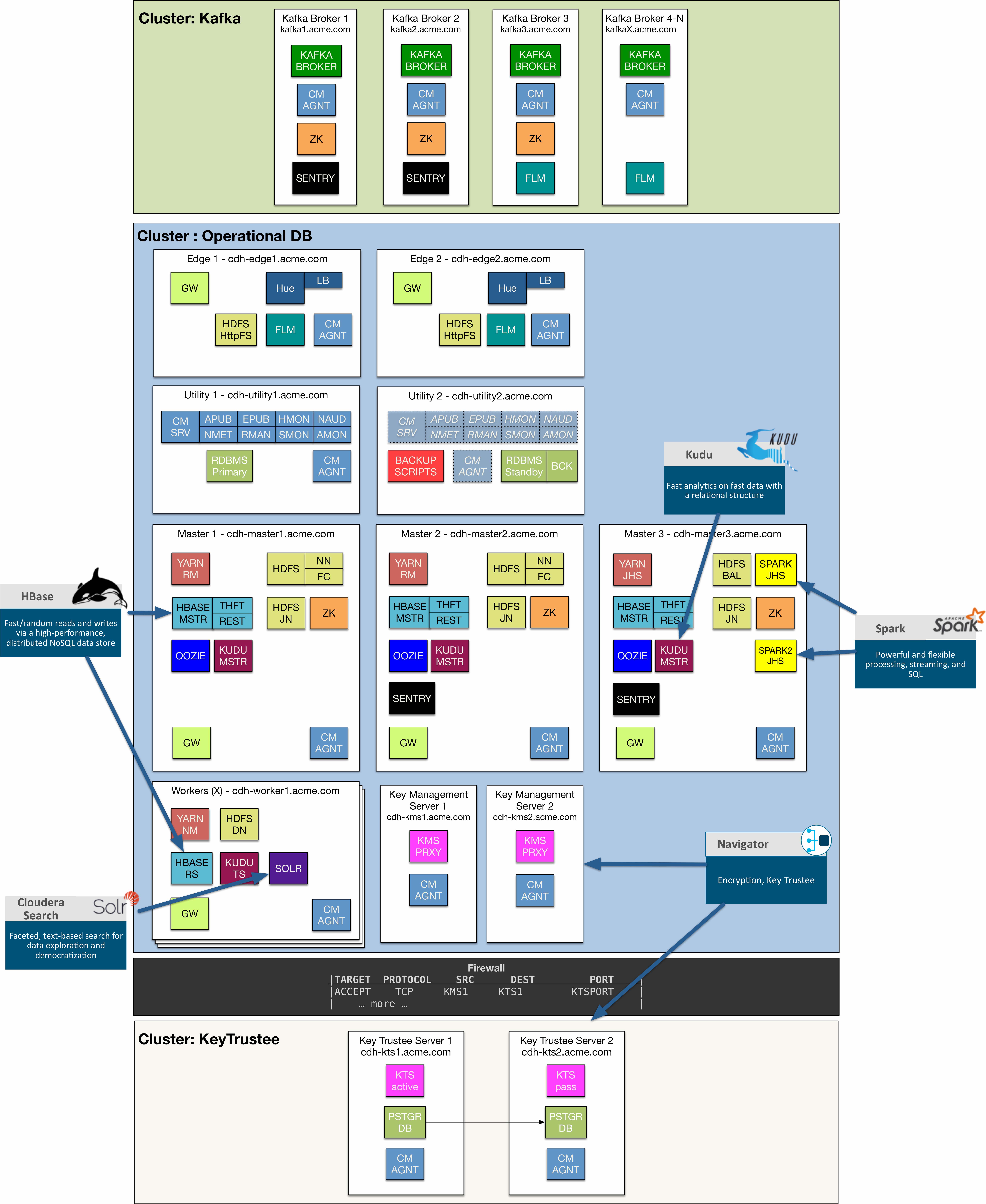
營運資料庫特定元件
HBase:在多個主節點之間部署一組HBase Master (HMaster)。所有工具節點上均部署RegionServers。透過ZooKeeper 協調高可用性,決定要導向哪個HMaster 請求。
Cloudera Search:Cloudera Search 由數個元件組成,包括部署在所有工具節點之間的Solr。Hue 是Cloudera Search 的另一個元素,為搜尋儀表板提供各項功能。若是Solr 伺服器故障,在多個Solar 伺服器之間應複製Solr 集合,以便全面達到高可用性。
Kudu:請參閱分析資料庫部分的說明,因為Kudu 服務角色配置相同。
Spark 和Spark2:請參閱分析資料庫部分的說明,因為Spark 服務角色配置相同。
Navigator:Navigator 加密和Key Trustee 已經在上面的分析資料庫部分說明過。
Kafka:Kafka 應常駐在本身的叢集上,不過它可能由管理營運資料庫叢集的同一個Cloudera Manager 管理。另外的Zookeeper 叢集搭配一對Sentry 角色部署,橫跨首幾個Kafka Brokers。若有必要使用Flume 服務從上游來源提取資料時,在Kafka Brokers 上可能有Flume 服務,並利用Kafka sink 或是Kafka 頻道提供事件到Kafka 叢集中。
其餘服務是平台的通用服務,之前在分析資料庫的部分已有敘述。
Data Science and Engineering
Data Science and Engineering 是由下列一組核心、高層級的元件提供支援。
這些元件提供所有必需的常見和高效能的工具,以應付預測性分析的所有層面。 您將能夠大規模執行進階的探索性資料科學與機器學習,無論是在內部部署的平台、在公有雲之間或兩者皆有。
Data Science Workbench 是現代化、功能完整、安全、彈性和可擴充的環境,讓資料科學家能夠用前所未見的方式探索資料和提出深入分析。 它允許透過程式設計語言例如R、Python 和Scala 存取資料並提供最愛的程式庫和框架。
在這個多租戶環境中透過Navigator 維持稽核、資料歷程、加密、金鑰管理等仍然十分重要,因為您的資料科學家和工程師來自組織的不同部門,而且十分瞭解如何與資料互動。
資料科學家工具組中另一項必需工具就是能夠使用Hue 和Solr 搜尋各種類型的資料集。即使如此,傳統SQL 透過Hive 存取資料集的功能仍然十分重要,因為Spark 是大規模處理這些資料的理想標準。
最後,所有這些工具均會啟用並針對雲端最佳化,讓部署更簡易,提高擴充彈性。
指派服務的方式可能如下圖所示:
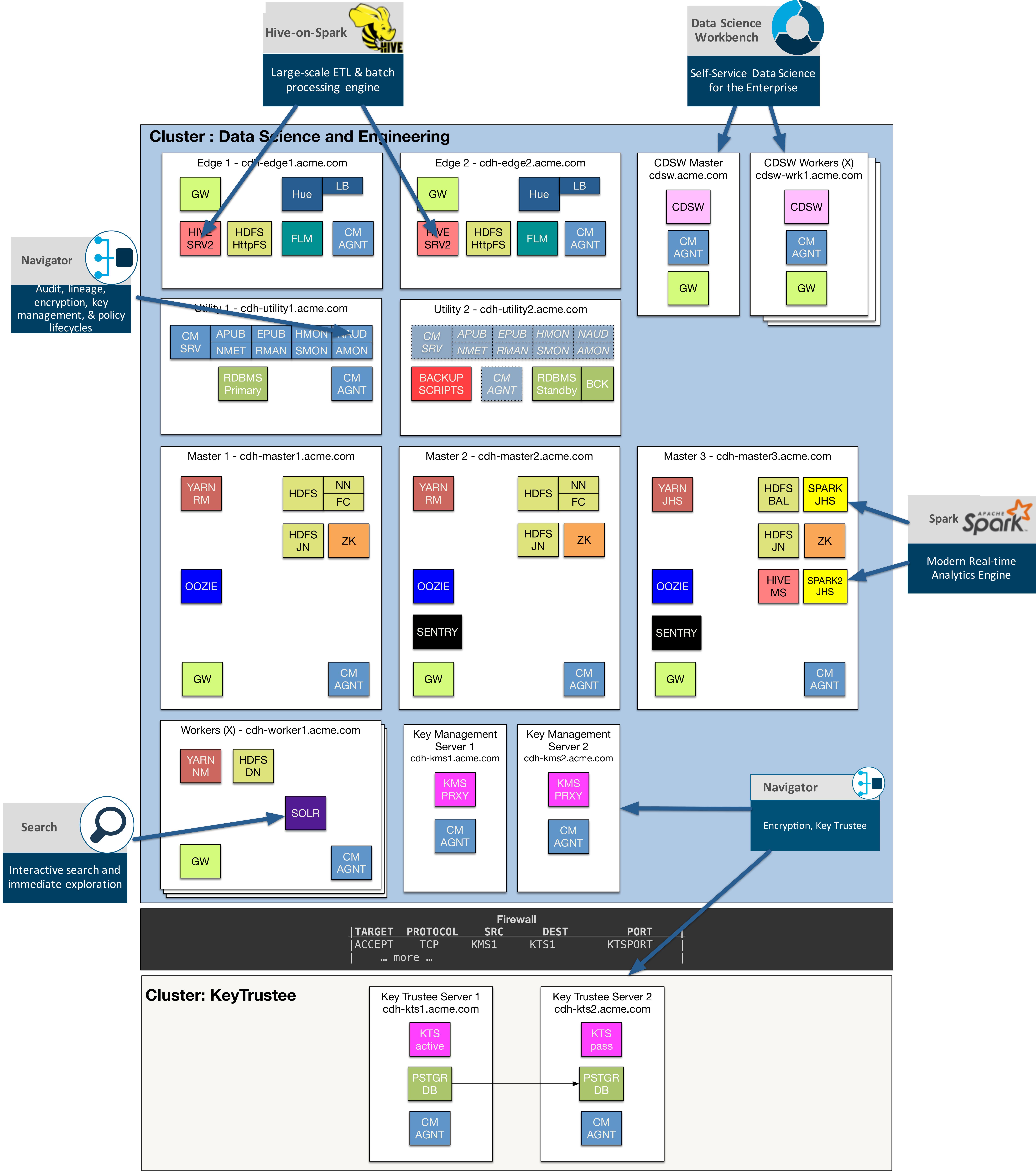
資料科學和工程特定的元件
在上述關於分析資料庫或營運資料庫的小節中未提及的唯一一個重要的服務,就是Cloudera Data Science Workbench (CDSW)。關於組成這個產品的所有其他元件,Navigator、Search、Hive-on-Spark 和Spark,請參閱前文中敘述這些服務之安排的小節。
Cloudera Data Science Workbench (CDSW):CDSW 初始即含有一個主節點,該節點也可以在啟動時當作工作節點。當您讓更多資料科學家和工程師使用這些功能時,您可以新增更多工作節點來擴充。我們需求萬用的子網域,例如*.cdsw.acme.com來隔離使用者產生的內容,並且務必要查閱CDSW要求與支援平台文件,瞭解其他要求和擴充指引。
結論
在這篇「第二部分:服務與角色配置」部落格文章中,我們深入探討Cloudera 服務與角色應該安排在叢集中各個節點之間的哪些地方。我們使用三種不同的產品作為使用案例,來建置可以部署在公司內部和公有雲的專屬用途叢集。請留意本系列文章的第三部分,我們將討論部署Cloudera Enterprise 時具體的雲端考量事項。
